
Monoliths will make a comeback
Alternative approaches to solving sociological problems with technical solutions

While reading about how Prime Video moved from a distributed microservices architecture to a monolithic application reducing costs by 90%, I started to think more about how teams choose between microservices vs monolithic design patterns.
One immediately clear observation from being in engineering organizations of various sizes is that one size doesn’t not fit all. The scale of the engineering team (“at scale” referring to an eng team with 100+ developers), and the various transitions that occur throughout the lifecycle of a company are what dictate the architecture (eg: focusing on building out features to test out new markets, focusing on reliability/KTLO, etc).
A serverless(-based microservice) first approach makes a lot of sense - quick prototyping when you’re trying to figure out what exactly should get built. When you have to support a higher load, you need to consider security, reliability, developer experience in the workload management system, be it containerized or not. The growth of complexity is usually directly proportional to heaver and chattier logic in backend code - generally speaking, a lot of this working code can then be repurposed to function within a single long-running microservices which are horizontally scaleable.
If you think about why microservices architectural patterns exist in the first place , it was to parallelize opportunities for innovation and improvements to the larger subsystem. Conway’s law states,
“Organizations, who design systems, are constrained to produce designs which are copies of the communication structures of these organizations.”
When a group of people get together to start solving a problem, the team size is relatively small and communication is efficient. As the size of the software and the team grows, we like to componentize the software to reflect the communication structures of the subteams. Each component within a large piece of software is usually designed by individual teams that sit within a larger organizational hierarchy. With a service-oriented architecture (SOA), each component can be its own team with its own roadmaps, OKRs, KPIs, etc. As engineering teams grow, they inevitably end up stepping on each others’ toes. The reasonable path forward was to implement a construct and orchestration model that prevents this, allowing services to evolve somewhat independently. Enter microservices.
With this move, we’ve distributed the potential problem of engineering hygiene from one (monolithic) process to a real problem of multiple (microservice) processes connected over some network.
Kelsey Hightower, one of the biggest advocates of Kubernetes, wrote:
“We’re gonna break [the monolith] up and somehow find the engineering discipline we never had in the first place… Now you went from writing bad code to building bad infrastructure that you deploy the bad code on top of.”
In the past, we had various specialties in engineering (database engineer, network engineer, etc) - with the move to microservices, every product engineer now has to think not only about their product’s features but also about the infrastructure that their components run on, and how it interacts with the broader constellation of services. But one thing is for certain, it's much easier to write a new API than to communicate/convince a different team about a change that you’re proposing (cause the engineering mind optimizes for efficiency, and since it knows that the code will have to get written at the end anyway, why not do it upfront?).
Horse-trading is a reality for most engineering organizations (and frankly, central to how humans work). “If I do this for you, in what areas will it help me?” There are two models that are worth considering:
Making source code changes to get your feedback on how to incorporate the proposed the design into both your component and mine (easier with monoliths)
Coming with an opinionated view of what my component is (in somewhat of an isolation to how your system works internally), and figuring out how to integrate with your system (easier with microservices)
I’d argue that the communication still has to happen. In the microservices world, technical leadership has simply made collaboration more challenging/expensive by decentralizing it.

With the principles of microservices fully entrenched, next came polyrepos. Since the monolith was deployed from a single repository, the thought when adopting microservices was to split code into many different repositories, thus the polyrepo was born., Most teams believe this promotes “greater agility”. When I was at Uber we went through a similar journey of breaking apart two monoliths. We felt these monoliths were constraining product delivery and we wanted to adopt a model that empowered engineering teams to move like “speedboats” - this resulted in a massive microservice sprawl spanning 4500+ polyglot microservices, backed by an equivalently large number of polyrepos. Many other big tech companies have gone through the same cycles, DoorDash went through a similar journey not too long ago.
But when we talk about engineering execution, we usually over-optimize about how we can ship faster in the near term. I suspect this is due to the “grass is greener” syndrome.
All of this doesn’t seem too bad on paper, right? When this kind of architectural transition is well supported, communicated, and funded it can work really well. But there’s a few practical considerations worth considering. Infrastructure teams are usually not as heavily funded as product engineering teams, therefore, the cost of managing, maintaining and securing these repositories, and their underlying infrastructure becomes an exponentially more challenging task. Whereas a monolith usually comes from one repository, with microservices the usual first strategy is to seed them from multiple smaller-sized repositories - we end up with a diagram that looks like this.

Additionally, there are many engineering culture and tooling considerations that go into picking between monorepos and polyrepos, and there has been furious debates arguing for either side that I’ll refrain from going into further detail on here. This was about how source code goes from a developer’s IDE, takes on a set of changes that the developer intends to make, and gets transformed to run as production workloads.
Everything we’ve talked about so far has been about the stateless side of the infrastructure. But state matters! When it comes to state, microservices usually end up with their own persistence layer, be it databases for online storage (eg: MySQL, Redis, etc), or for offline storage (eg: Hadoop, Snowflake, etc) or for streaming (eg: Apache Kafka, AWS SQS/SNS, etc). From a distributed systems standpoint, we know that domain-specific data should stay as close to the domain authority as possible. But lack of attention to how data is stored leads to various issues with data duplication and obfuscates singular data authority/source-of-truth perspective - as I’m sure we’ve all experienced, duplicated data never stays in sync. Now, we can add state to the diagram from before - a simplified representation of how the persistence layer gets quite distributed as monolithic applications are broken down.
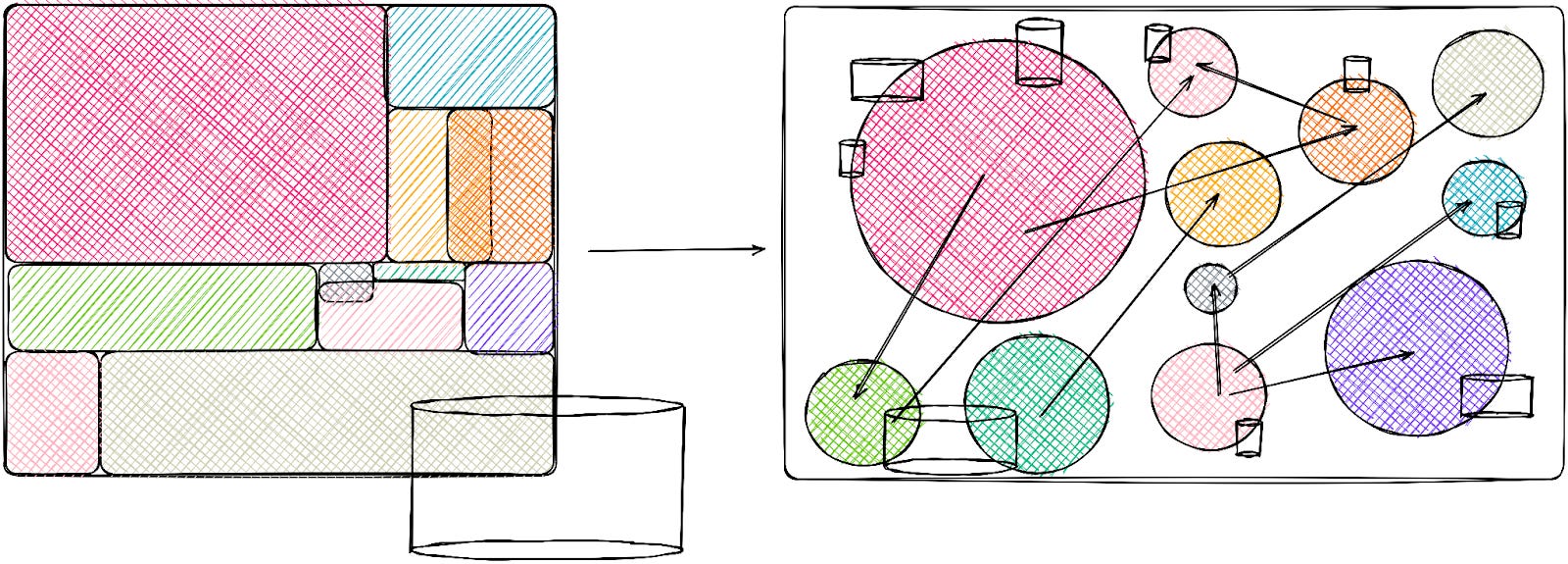
A couple of general, somewhat oversimplified, changes happen as monoliths transition to microservices:
Method/function calls are now replaced with network calls
Module-level separations are replaced with service partitioning
Right when the transition happens, general velocity does increase quite a bit but it’s arguable whether that rate is commensurate with the rate at which technical complexity increases. The relative complexity is often underestimated due to its inherent decentralization. Teams end up duct-taping software to “just make it work” and ship fast.
And as the microservice sprawl gradually increases, a new need emerges. The need for centralized API schema registries - because without these, services can’t serialize their network calls to downstream services and establish proper API contracts. Microservices also need to constantly be mindful of backward-compatible API changes (or upstream services will suddenly stop working and no one will know why the overall system is malfunctioning). This is true for components/modules in monoliths too, but provided proper validation is in place within your Monolith, breaking API changes are usually discovered much sooner in the SDLC
As teams grow, it becomes challenging to prevent duplication of efforts and functionalities. So we start to say “we need some centralized review processes to prevent x,y,z...” But, the engineering mind (correctly) perceives this as red tape and bureaucracy.

We start getting back to the notion that we need a source of truth, which usually manifests itself as a central authority, which is not distributed (since anything distributed usually has a latency associated with driving consensus). Now, the centralization that we were trying to democratize slowly starts coming back at each stage.
In my experience in big tech, career advancement for engineers also gets interlinked with introducing new (micro)services - this is an unintended side-effect that results from the sprawl and a potentially misaligned engineering culture. Sometimes, older services are rewritten to build new microservices, either with new functionality or performance upgrades. More often than not, legacy versions of these services are not fully decommissioned and consumers aren’t fully migrated to the new service, leading to further increases in maintenance and operating costs.
Microservices are an attempt at solving a sociological problem with a technical solution.
Engineering teams have a problem with x so they look into a solution y without considering a, b, c. Admittedly, at a certain scale, being able to break a large system down into components that large teams can operate on, independently, makes logical sense, but most companies are not Google, Uber, Stripe or Netflix. Even Meta (formerly Facebook) has managed to get by with a pretty monolithic architecture!
I’d argue that most technological issues with monoliths can be solved with improved tooling that helps to maintain and enhance engineering velocity. These solutions often get overlooked as they aren’t as “shiny” as a fancy new architectural pattern. None of this is to say that microservices are inherently bad, but they aren’t a panacea and often simpler solutions exist. Given the large microservice sprawl that we’re now seeing at many engineering companies, I wouldn’t be surprised to see monoliths make a comeback, but this time with a better, more robust set of tooling for development (there will be a future post covering this) and testing that doesn’t sacrifice product velocity or developer happiness.
This was really eye-opening in a few ways. Can you expand on the function of “central registries”, ie, is this used to track all consumers of APIs to microservices?